In dieser Übung werden wir üben wie man von Hand und mit Hilfe von R einen Binomialtest und Chi-Quadrat test berechnet und die jeweiligen Ergebnisse interpretiert. Wenn Sie einige Inhalte der Vorlesung nochmal vertiefen wollen, oder nochmal eine ausführlichere Erklärung für die Anwendung des Binomialtests oder Chi-Quadrattests in R haben wollen, dann können Sie sich die folgenden Videos anschauen:
In den folgenden Übungen können Sie entweder den simulierten Datensatz semester_data2.csv nutzen, oder Sie können die in den Aufgaben angegebenen Häufigkeitstabellen die auf Basis des Datensatzes ausgerechnet wurden verwenden um die jeweiligen Tests von Hand zu rechnen. Der Datensatz enthält die Variablen: geschlecht, nationalität, wohnort, alter, wissen_statistik und grösse.
Zum Teil basieren die Werte auf simulierten Daten, die nicht in dem Datensatz enthalten sind.
head(semester_data2)
geschlecht nationalität wohnort alter wissen_statistik grösse
1 weiblich Schweiz Luzern 21.9 3 158
2 weiblich Frankreich Bern 24.0 2 159
3 weiblich Schweiz Zug 21.2 3 168
4 weiblich Frankreich Zuerich 27.0 2 178
5 weiblich andere St. Gallen 17.7 4 164
6 weiblich Schweiz Bern 22.0 3 166
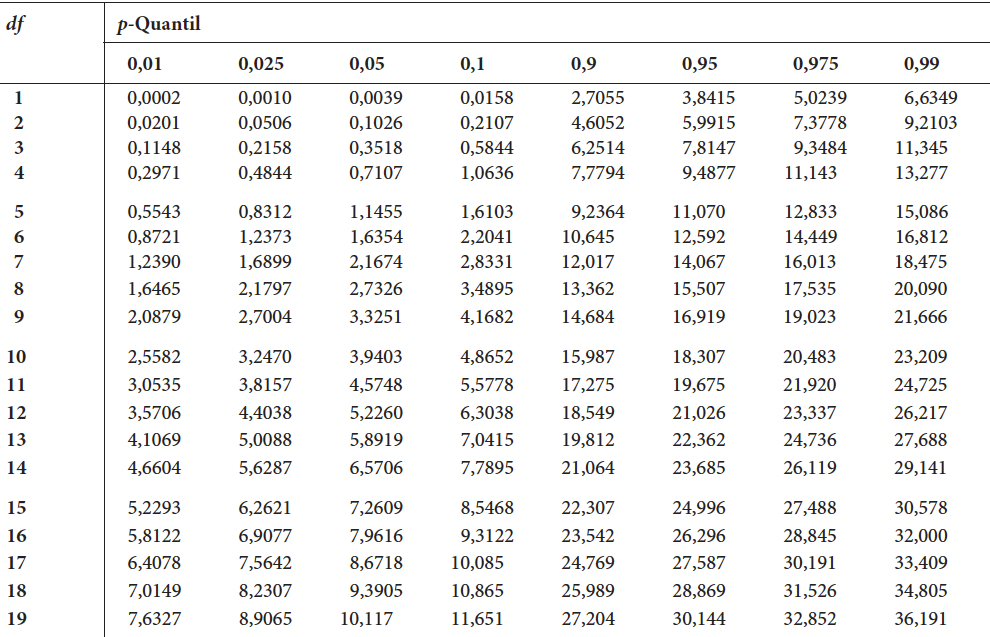
Falls Sie die Übungsfragen nicht mit R beantworten wollen, dann können Sie die hier gedruckte Tabelle der p-Quantile der \(\chi^2\)-Verteilung nutzen um die Fragen zu beantworten.
Tabelle der p-Quantile der \(\chi^2\)-Verteilung
Wie in den bisherigen Übungen finden Sie über den Übungsaufgaben die webr Konsole, die Ihnen das Schreiben und Durchführen von R Code direkt auf der Website ermöglicht. Wenn viele Studierenden die Übungen parallel machen, dann kann es sein, dass webr langsam wird.
Um den Code den Sie geschrieben haben auszuführen drücken Sie entweder Run Code, damit der gesamte Code ausgeführt würde. Alternativ können Sie auch einzelne Zeilen ausführen, indem sie CRTL+Enter (Windows) oder CMD+Enter (Mac) drücken.
Nutzen Sie eine Suchmaschine, wenn Sie nicht wissen welche Funktionen Ihnen ein bestimmtes Ergebnis liefern. Ausserdem können Sie in R immer die Hilfe einer Funktion aufrufen, indem sie vor den Namen der Funktion ein Fragezeichen schreiben, z. Bsp ?median oder die Hilfe-Funktion help() mit dem jeweiligen Funktionsbefehl ausführen: help(median).
Sie haben die folgenden Kreuztabelle zu den Ergebnissen der Prüfung in Statistik 1 von 200 Studierenden.
männlich
weiblich
bestanden
39
104
nicht bestanden
5
52
Berechnen Sie die erwarteten Häufigkeiten unter der Annahme, dass die Wahrscheinlichkeiten die Prüfung zu bestehen unabhängig davon ist, ob Studierenden männlich oder weiblich sind. (Geben Sie für alle Häufigkeiten 2 Nachkommastellen an und nutzen sie einen Punkt als Dezimaltrennzeichen)
männlich
weiblich.
Summe
bestanden
nicht bestand.
Summe
Berechnen Sie zusätzlich auf Basis der erwarteten Häufigkeiten den empirischen Chi-Quadrat-Wert für den Test auf unabhängigkeit: \(\chi^2_{emp} =\)
Um die erwateten Häufigkeiten zu berechnen müssen wir zuerst die marginalen Häufigkeiten für die Zeilen und Spalten berechnen. Dabei ergibt sich für die Häufigkeiten die Prüfung zu bestehen oder nicht zu bestehen:
x
bestanden
143
nicht bestanden
57
und für die Häufigkeiten von männlichen und weiblichen Studierenden:
x
männlich
44
weiblich
156
mit diesen Werte können wir nun auf Basis der Formel \(n_{ij} = \frac{n_i \cdot n_j}{N}\) mit \(N\) gleich der Stichprobengrösse 200. Die erwarteten Häufigkeiten in den einzelnen Zellen berechnen. Dabei sollten Sie mit den oben berechneten Werten auf die folgenden Kreuztabelle der Erwarteten Häufigkeiten kommen:
männlich
weiblich
bestanden
31.46
111.54
143
nicht bestanden
12.54
44.46
57
44.00
156.00
200
Für die Berechnung der empirischen Chi-Quadrat Wertes müssen wir zuerst wieder die Differenz zwischen beobachteten und erwarteten Häufigkeiten berechnen:
männlich
weiblich
bestanden
7.54
-7.54
nicht bestanden
-7.54
7.54
diese Abweichungen quadrieren wir dann wiederum und teilen Sie durch die erwarteten Häufigkeiten:
männlich
weiblich
bestanden
1.81
0.51
nicht bestanden
4.53
1.28
Wenn wir diese Werte nun aufsummieren kommen wir auf den empirischen Chi-Quadrat Wert: \(\chi^2_{emp} = 8.13\)
Sie wollen für die Stichprobe aus dem Datensatz semester_data2.csv testen, ob die Wahrscheinlichkeit das eigenen Statistikwissen sehr hoch einzuschätzen (d.h mit einer 5 zu Bewerten) von 0.05 abweicht. Aus dem Datensatz haben Sie berechnet, dass 12 von 180 Personen ihr Statistikwissen sehr hoch einschätzen. Der Output des Binomialtests den Sie mit R berechnet haben sieht folgendermassen aus:
Welche der folgenden Aussagen für einen Test mit dem Signifikanzniveau von \(\alpha = .10\) ist korrekt?
Die letzte Zeile des Output gibt die Stichprobenschätzung sample estimates der Wahrscheinlichkeit sein Statistikwissen als hoch einzuschätzen wieder. Diese wird gerundet als \(P_{emp} = 0.067\) angegeben.
Der \(p\)-Wert für das beobachtete oder extremere Ergebnisse unter Annahme der \(H_0\) liegt laut dem Output bei \(p = .302\). Dieser Wert ist grösser als das Signifikanzniveau \(\alpha = .10\), entsprechend ist der Test nicht signifikant.
Auch wenn der \(p\)-Wert bei \(p = .302\) liegt, kann dieser nicht als Wahrshceinlichkeit, dass die Nullhypothese in der Population gilt interpretiert werden. Der \(p\)-Wert ist die Wahrscheinlichkeit das beobachtete oder extremere Ereignisse unter Annahme der \(H_0\) zu erhalten.
Auf Basis der Alternativhypothese alternative hypothesis: true probability is not equal to 0.05 können wir schliessen, dass ein ungerichteter Test durchgeführt wurde. Wichtiges Stichwort ist not eqaul anstatt von less oder greater für gerichtete Hypothesen.
Aus dem vorangegangen Semester wissen Sie das die Wahrscheinlichkeit für den Wohnort der Studierenden folgender Wahrscheinlichkeitsverteilung folgt:
Basel
Bern
Luzern
St.Gallen
Zuerich
Zug
0.08
0.25
0.3
0.12
0.18
0.07
Im aktuellen Semester haben Sie von 180 Studierenden die folgenden Häufigkeiten des Wohnorts beobachtet:
Basel
Bern
Luzern
St.Gallen
Zuerich
Zug
17
41
50
30
29
13
Berechnen Sie einen \(\chi^2\)-Test mit Signifikanzniveau \(\alpha = .05\) um zu Testen, ob die Häufigkeitsverteilung des aktuellen Semester sich statistisch bedeutsam von der Wahrscheinlichkeitsverteilung des letzten Semesters unterscheidet.
Kreuzen Sie für den Test an welche der folgenden Antworten korrekt ist.
Als erstes müssen wir die erwarteten Häufigkeiten aus der Wahrscheinlichkeitsverteilung und der Anzahl an Studierenden berechnen. Dafür müssen wir die Wahrscheinlichkeiten für jede Zelle mit der Stichprobengrösse multiplizieren.
Basel
Bern
Luzern
St.Gallen
Zuerich
Zug
14.4
45
54
21.6
32.4
12.6
Mit diesen Werten können wir nun die quadrierten Abweichungen zwischen den beobachteten und erwarteten Häufigkeiten berechnen, durch die erwartete Häufigkeit teilen und entsprechend der Formel für den empirischen \(\chi^2\)-Wert aufsummieren.
Hier sehen Sie die Tabelle der quadrierten Abweichungen:
Basel
Bern
Luzern
St.Gallen
Zuerich
Zug
6.76
16
16
70.56
11.56
0.16
und hier sind die Quadrierten Abweichungen durch die erwarteten Häufigkeiten geteilt:
Basel
Bern
Luzern
St.Gallen
Zuerich
Zug
0.469
0.356
0.296
3.267
0.357
0.013
Wenn sie die Werte aus der letzten Tabelle aufsummieren erhalten sie den empirischen Chi-Quadrat wert: \(\chi^2_{emp} = 4.76\).
Den kritischen Testwert können Sie aus der Tabelle der \(p\)-Quantile der \(\chi^2\)-Verteilung ablesen. Dafür müssen wir bestimmen, dass die Freiheitsgrade des Tests die Anzahl an Zellen der Häufigkeitstabelle minus 1 sind: \(df = n-1 = 6 - 1 = 5\) und wir in der Zeile für das \(p\)-Quantil von \(p = 1 - \alpha = 1 - .05 = .95\) ablesen müssen. Mit diesen werten sollten Sie den kritischen Chi-Quadrat-Wert als: \(\chi^2_{krit}(df = 5) = 11.07\) finden.
Weil der empirische Chi-Quadrat Wert kleiner oder gleich dem kritischen Chi-Quadrat Wert ist, ist der Test nicht signifikant.
In R könnten Sie den Test folgendermassen durchführen: