Übung 8 - Inferenzstatistik
HS 2025
Wiederholung & Vertiefung: Parameterschätzung
In dieser Übung werden wir Üben mit den Konzepten der Parameterschätzung und Konfidenzintervallen zu arbeiten. Wenn Sie die Inhalte der Vorlesung nochmal vertiefen wollen, dann empfehle ich Ihnen die folgenden Videos. Beachten Sie das das erste Videos etwas tiefer in die mathematischen Grundlagen des Zentralen Grenzwertsatzes und der Normalverteilung einsteigen. Dieses Video ist als Verteifung für interessierte Studierende gedacht, die konzeptuelle Grundlagen hinter der Normalverteilung besser verstehen wollen. Es wird nicht erwartet, dass Sie die mathematischen Ableitungen auswendig können und selbst anwenden können. Dennoch hilft Ihnen das Videos ein besseres Verständnis für die Normalverteilung und ihre Relevanz in der Statistik zu bekommen:
Übungen
In den folgenden Übungen nutzen Sie keinen konkreten Datensatz, sondern werden anhand von Verteilungsannahmen und theoretischen Populationsparametern Hypothesen formulieren, Kritische Werte berechnen und Hypothesentests für Einzelfälle durchführen. Nutzen sie R dabei einfach als Taschenrechner.
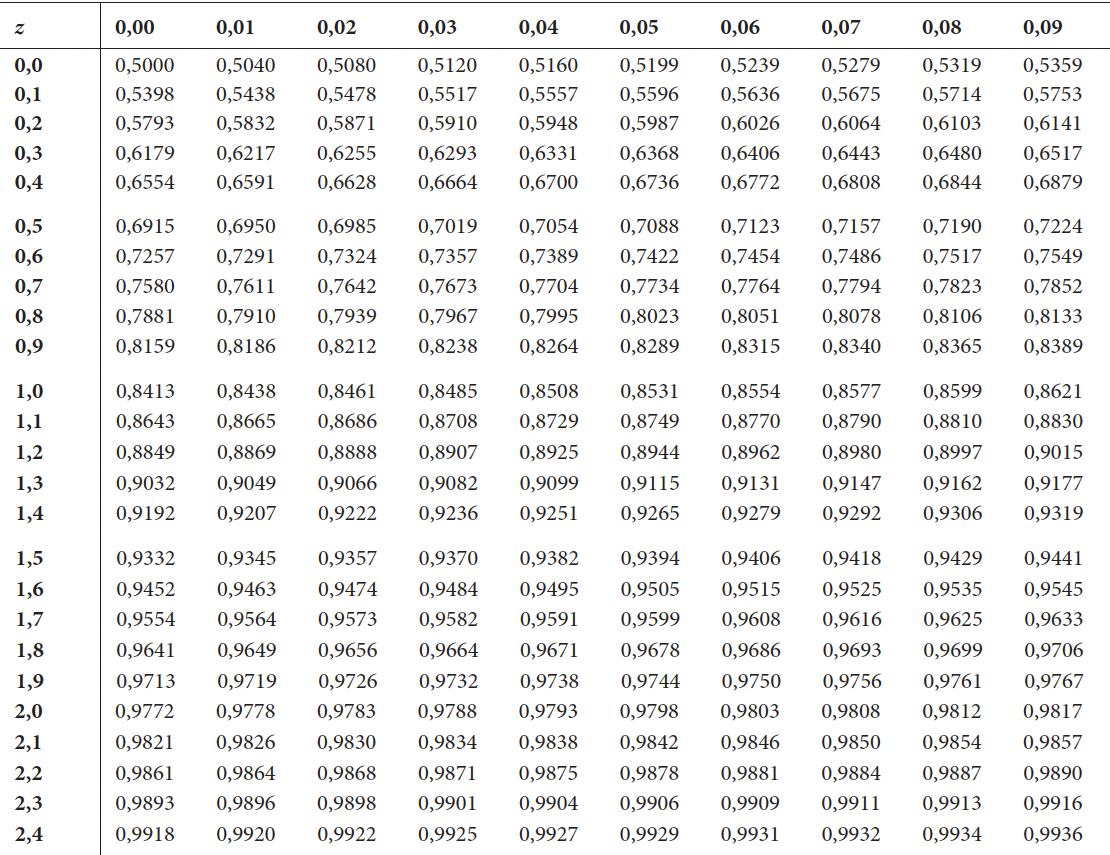
Falls Sie die Übungsfragen nicht mit R beantworten wollen, dann können Sie die hier gedruckte Tabelle der z-Werte der Verteilungsfunktion der Standardnormalverteilung nutzen um die Fragen zu beantworten.
Beachten Sie, dass sie für die Nutzung der Tabelle der z-Werte ihre unstandardisierten Ergebnisse \(X\), für die wir in der Regel annehmen, dass sie einer Normalverteilung folgen, in \(z\)-Werte transformieren müssen, die einer Standardnormalverteilung folgen.
\[ z = \frac{X - \mu}{\sigma} \]
Wie in den bisherigen Übungen finden Sie über den Übungsaufgaben die webr Konsole, die Ihnen das Schreiben und Durchführen von R Code direkt auf der Website ermöglicht. Wenn viele Studierenden die Übungen parallel machen, dann kann es sein, dass webr langsam wird.
Hinweis: Sie können üben die Berechnungen und Umformungen, die Sie in der Prüfung durchführen müssen, auch mit Hilfe von R durchzuführen. Wenn Sie dies machen wollen, dann erlauben Sie sich einfach nicht der Verteilungs- und Quantilfunktion der Normalverteilung (pnorm und qnorm) zusätzlich einen Mittelwert mean und eine Standardabweichung sd als Argumente zu übergeben. Damit dienen die Funktionen einfach dem Ablesen aus der Verteilungstabelle für die Standardnormalverteilung und sie müssen die Aufgaben trotzdem über die Berechnung von \(z\)-Werten lösen.
Um den Code den Sie geschrieben haben auszuführen drücken Sie entweder
Run Code, damit der gesamte Code ausgeführt würde. Alternativ können Sie auch einzelne Zeilen ausführen, indem sie CRTL+Enter (Windows) oder CMD+Enter (Mac) drücken.
Nutzen Sie eine Suchmaschine, wenn Sie nicht wissen welche Funktionen Ihnen ein bestimmtes Ergebnis liefern. Ausserdem können Sie in R immer die Hilfe einer Funktion aufrufen, indem sie vor den Namen der Funktion ein Fragezeichen schreiben, z. Bsp
?medianoder die Hilfe-Funktionhelp()mit dem jeweiligen Funktionsbefehl ausführen:help(median).
Sie wollen Testen, ob männliche Studierenden statistisch bedeutsam grösser sind als weibliche Studierende. Sie wählen dafür ein Signifkanzniveau von \(\alpha = .01\). Sie wissen, dass die Grösse von Frauen im Alter von 18 bis 30 in der Schweiz einer Normalverteilung mit dem Mittelwert \(\mu_W = 165\) und der Standardabweichung \(\sigma_W = 7\) folgt und nehmen an, dass das auch für weibliche Studierende gilt.
Für die Planung der Untersuchung nehmen Sie an das männliche Studierende einer Normalverteilung mit Mittelwert \(\mu_M = 175\) und Standardabweichung \(\sigma_M = 7\) folgen. Wie gross muss ihre Stichprobe sein, damit das nach unten geschlossene Konfidenzintervall des Mittelwerts der Stichprobe der männlichen Studierenden, den Mittelwert der Verteilung der Frauen nicht einschliesst? Nehmen Sie dafür an, dass der beobachtete Mittelwert \(\bar{x}\) dem Mittelwert der Populationsverteilung der Männer entspricht.
Um diese Frage zu beantworten müssen wir als erstes die Formel zur Berechnung der unteren Grenze eines nach unten Geschlossenen einseitigen Konfidenzintervalls betrachten:
\[ \bar{x}_{M} - z_{0.99} \cdot \frac{\sigma_{x_M}}{\sqrt{N}} \]
Für die Planung muss dieser Wert grösser sein als der Mittelwert der Grössenverteilung der Frauen \(\mu_W\)
\[ \bar{x}_{M} - z_{0.99} \cdot \frac{\sigma_{x_M}}{\sqrt{N}} > \mu_W \]
Um nach der gefragten Stichprobengrösse \(N\) aufzulösen müssen wir die Ungleichung nach \(N\) auflösen:
- Zu beiden Seiten \(z_{0.99}\frac{\sigma_{x_M}}{\sqrt{N}}\) addieren.
\[ \bar{x}_{M} > \mu_W + z_{0.99} \cdot \frac{\sigma_{x_M}}{\sqrt{N}}; \]
- Von beiden Seiten \(\mu_W\) abziehen.
\[ \bar{x}_{M}- \mu_W > z_{0.99} \cdot \frac{\sigma_{x_M}}{\sqrt{N}}; \]
- Beide Seiten durch \(z_{0.99} \cdot \sigma_{x_M}\) teilen
\[ \frac{\bar{x}_{M}- \mu_W}{z_{0.99} \cdot \sigma_{x_M}} > \frac{1}{\sqrt{N}}; \]
- Für beide Seiten den Kehrwert nehmen
\[ \frac{z_{0.99} \cdot \sigma_{x_M}}{\bar{x}_{M}- \mu_W} > \sqrt{N}; \]
- Beide Seiten quadrieren.
\[ \left(\frac{z_{0.99} \cdot \sigma_{x_M}}{\bar{x}_{M}- \mu_W}\right)^2 > N \]
In diese umgeformte Ungleichung können wir nun die Werte aus der Aufgabenstellung, sowie den \(z\)-Wert für die gewünscht Konfidenz einsetzen. Den \(z\)-Wert können Sie entweder aus der Tabelle ablesen, indem sie den Wert für einen Wert grösser als .99 suchen. Oder Sie nutzen die Quantilfunktion in R für das gewünschte Konfidenzniveua qnorm(p = .99)
Wenn Sie die Berechnung in R durchführen ergibt sich dabei:
z_confidence <- qnorm(p = .99)
sigma_male <- 7
mean_male <- 175
mu_female <- 165
required_sample <- ((z_confidence * sigma_male)/(mean_male - mu_female))^2
# aufrunden um das ungleichheitszeichen zu beachten
ceil(required_sample)Damit kommen sie auf eine erfordeliche Stichprobengrösse von \(N = 3\). Sie müssen dabei jedoch beachten, dass wir hier angenommen haben, dass der Mittelwert der gezogenen Stichprobe dem Populationsmittelwert der Männer entspricht. In der Praxis ist es gut möglich, dass der Stichprobenmittelwert unter dem Populationsmittelwert liegt.
Sie werfen 30 mal einen fairen Würfel und zählen aller Ergebnisse zusammen. Bestimmen Sie das zweiseitige 90%-Konfidenzintervall für die Summe der Ergebnisse unter Annahme des Zentralen Grenzwerttheorems. Berechnen Sie dafür als erstes den Erwartungswert \(\mu\) und die Varianz \(\sigma^2\) der Wahrscheinlichkeitsverteilung für den fairen Würfel (siehe Vorlesung 5: Wahrscheinlichkeitstheorie 2).
Laut Zentralem Grenzwerttheorem folgt die Summe der Ergebnisse des widerholten Würfelwurfs einer Normalverteilung:
\[ \sum X \sim \mathcal{N}(N\cdot\mu, \sqrt{N} \cdot \sigma) \]
Um den Erwartungswert und die Standardabweichung der Verteilung der Summe der Ergebnisse zu berechnen müssen wir also zuerst den Erwartungswert und die Standardabweichung der Wahrscheinlichkeitsverteilung für einen Würfelwurf berechnen. Für einen fairen Würfel haben alle Ergebnisse von 1 bis 6 die gleiche theoretische Warhscheinlichkeit \(\pi = \frac{1}{6}\). Asu diesen Werten ergibt sich:
\[ E(X) = \mu = \sum_{i = 1}^j X_j \cdot \pi_j = 1 \cdot \frac{1}{6} + 2 \cdot \frac{1}{6} + 3 \cdot \frac{1}{6} + \dots + 6 \cdot \frac{1}{6} = 3.5 \]
\[ VAR(X) = \sigma^2 = \sum_{i = 1}^j (X_j - \mu)^2 \cdot \pi_j = (1−3.5)^2 \cdot \frac{1}{6} + (2−3.5)^2 \cdot \frac{1}{6}+ \dots + (6−3.5)^2 \cdot \frac{1}{6} = 2.916... \]
Mit diesen Werten können wir nun den Erwartungswert und die Standardabweichung der Verteilung der Summe aus \(N = 30\) Würfelwurfen berechnen:
\[ \mu_\sum = N \cdot \mu = 30 \cdot 3.5 = 105 \]
\[ \sigma_\sum = \sqrt{N} \cdot \sigma = \sqrt{N} \cdot \sqrt{\sigma^2} = \sqrt{30} \cdot \sqrt{2.916} = 9.35... \]
Mit diesen Werten können wir nun die Grenzen des Konfidenzintervalls berechnen
\[ 90\% KI = [\mu_\sum - z_{0.95}\cdot \sigma_\sum, \mu_\sum + z_{0.95} \cdot \sigma_\sum] \]
den relevanten \(z\)-Wert können wir in der Tabelle auslesen, oder mit Hilfe der Quantilfunktion in R bestimmen: qnorm(0.95), daraus ergibt sich \(z_{0.95} = 1.65\). Das Konfidenzintervall ist entsprechend:
\[ 90\% KI = [105 - 1.65 \cdot 9.35, 105 + 1.65 \cdot 9.35] \]
\[ 90\% KI = [89.62, 120.38] \]
Beachten Sie, dass wir an dieser Stelle das Konfindezintervall mit Hilfe der Standardabweichung berechnen, weil es sich um ein Ergebnis handelt das wir durch 30 Mal Würfeln erhalten. Die Stichprobe für das relevante Zufallsexperiment ist also 1.
Wenn Sie R als Taschenrechner nutzen, könnte eine Lösung folgendermassen aussehen:
ergebnisse <- 1:6
wahrscheinlichkeiten <- rep(1/length(results), length = length(results))
# Kennwerte der Wahrscheinlichkeitsverteilung eines Würfelwurfs
erwartungswert <- sum(ergebnisse*wahrscheinlichkeiten)
varianz <- sum((ergebnisse-erwartungswert)^2 * wahrscheinlichkeiten)
# Kennwerte der Normalverteilung der Summe aus 30 Würfelwürfen
anzahl_würfe <- 30
erwartungswert_summe <- anzahl_würfe * erwartungswert
varianz_summe <- anzahl_würfe * varianz
sd_summe <- sqrt(varianz_summe)
# Berechnung des erforderlichen z-Werts
z_95prozent <- qnorm(0.95)
# Berechnung der Grenzen des Konfidenzintervalls
untere_grenze <- erwartungswert_summe - z_95prozent * sd_summe
obere_grenze <- erwartungswert_summe + z_95prozent * sd_summe
untere_grenze
obere_grenzeBis auf kleine Rundungsfehler erhalten Sie damit die gleiche Lösung wie in den oben berechneten Gleichungen.
Sie wollen den Mittelwert der Grösse von Psychologiestudentinnen bestimmen. Sie wissen, dass die Grösse von Frauen im Alter von 18 bis 30 in der Schweiz einer Normalverteilung mit dem Mittelwert \(\mu = 165\) und der Standardabweichung \(\sigma = 7\) folgt. Wie gross muss ihre Stichprobe sein, wenn der Standardfehler für die Schätzung der Durchschnittlichen Grösse von Psychologiestudentinnen \(\sigma_{\bar{x}} = 1\) sein soll?
Um diese Frage zu beantworten müssen wir als erstes die Formel für den Standarfehler des Mittelwerts betrachten:
\[ \sigma_{\bar{x}} = \frac{\sigma_x}{\sqrt{N}} \]
Die Standardabweichung in der Popultion \(\sigma_x\) ist gegeben, ebenso ist angegeben, dass wir einen bestimmten Standardfehler \(\sigma_{\bar{x}}\) erreichen wollen. Wir müssen diese Formel also nach der Stichprobengrösse \(N\) auflösen.
Um nach der gefragten Stichprobengrösse \(N\) aufzulösen müssen wir die folgenden Schritte durchführen:
- Beide Seiten mit der Wurzel der Stichprobengrösse \(\sqrt{N}\) multiplizieren.
- Beide Seiten durch den Standardfehler des Mittelwerts \(\sigma_{\bar{x}}\) teilen.
- Beide Seiten quadrieren.
\[ \sigma_{\bar{x}} \cdot \sqrt{N} = \sigma_x; \quad \sqrt{N} = \frac{\sigma_x}{\sigma_{\bar{x}}}; \quad N = \left(\frac{\sigma_x}{\sigma_{\bar{x}}}\right)^2 \]
In diese umgeformte Formel, können wir nun die Werte aus der Fragestellung einsetzen. Wenn Sie dabei R als Taschenrechner nutzen wollen wäre den Code dafür:
required_SE <- 1
population_sd <- 7
required_Sample <- (population_sd/required_SE)^2Damit sollten Sie auf eine Stichprobengrösse von \(N = 49\) kommen, mit der Sie einen Standardfehler von \(\sigma_{\bar{x}} = 1\) erreichen.
![]()