Übung 7 - Inferenzstatistik
HS 2025
Wiederholung & Vertiefung: Hypothesentesten
In dieser Übung werden wir Üben mit den Konzepten des Nullhypothesentests und des Binären Entscheidungskonzepts zu arbeiten. Wenn Sie die Grundlegenden Konzepte der Vorlesung nochmal wiederholen und Vertiefen wollen, dann empfehle ich Ihnen die folgenden Videos:
Beachten Sie das einzelne Konzepte aus den Videos noch nicht vertieft in der Vorlesung behandelt wurden aber in den nächsten Sitzungen auch eingeführt werden. Insofern können Sie die Videos (insbesondere das Video zu Hypothesentests) als eine Vorbereitung auf die Nächsten Sitzungen nutzen.
Übungen
In den folgenden Übungen nutzen Sie keinen konkreten Datensatz, sondern werden anhand von Verteilungsannahmen und theoretischen Populationsparametern Hypothesen formulieren, Kritische Werte berechnen und Hypothesentests für Einzelfälle durchführen. Nutzen sie R dabei einfach als Taschenrechner.
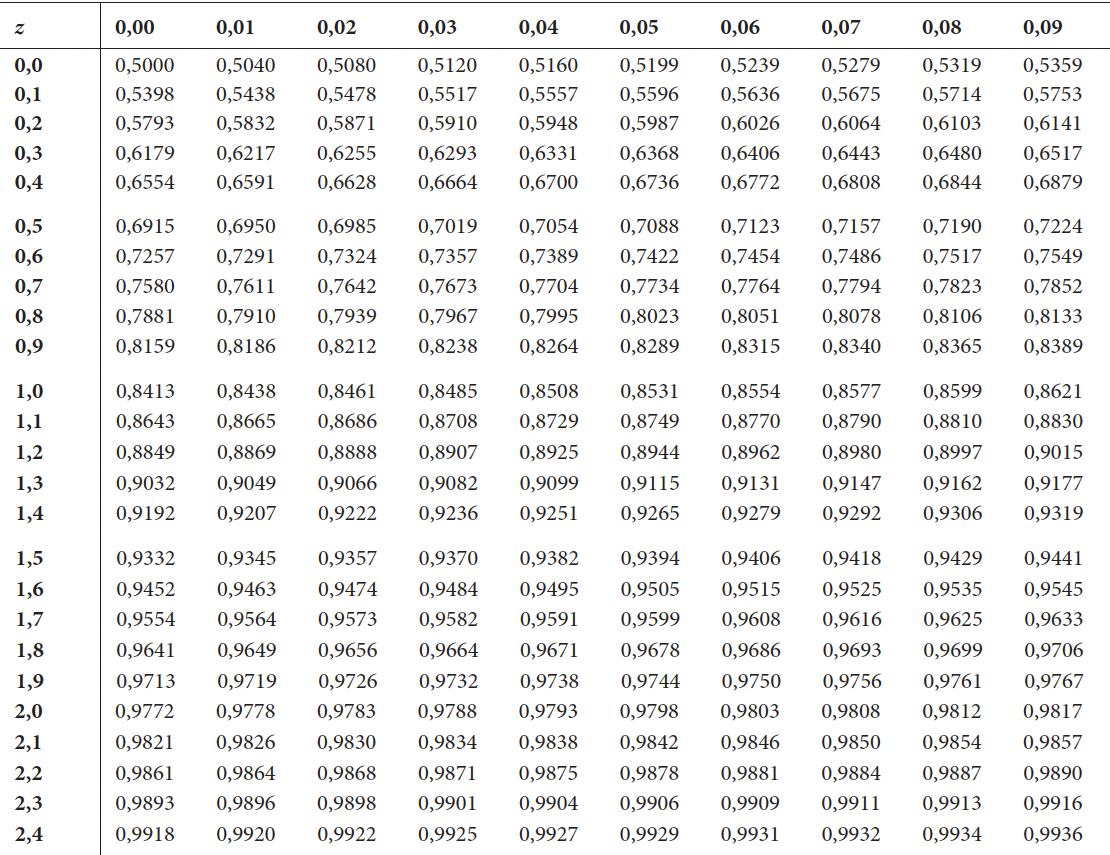
Falls Sie die Übungsfragen nicht mit R beantworten wollen, dann können Sie die hier gedruckte Tabelle der z-Werte der Verteilungsfunktion der Standardnormalverteilung nutzen um die Fragen zu beantworten.
Beachten Sie, dass sie für die Nutzung der Tabelle der z-Werte ihre unstandardisierten Ergebnisse \(X\), für die wir in der Regel annehmen, dass sie einer Normalverteilung folgen, in \(z\)-Werte transformieren müssen, die einer Standardnormalverteilung folgen.
\[ z = \frac{X - \mu}{\sigma} \]
Wie in den bisherigen Übungen finden Sie über den Übungsaufgaben die webr Konsole, die Ihnen das Schreiben und Durchführen von R Code direkt auf der Website ermöglicht. Wenn viele Studierenden die Übungen parallel machen, dann kann es sein, dass webr langsam wird.
Um den Code den Sie geschrieben haben auszuführen drücken Sie entweder
Run Code, damit der gesamte Code ausgeführt würde. Alternativ können Sie auch einzelne Zeilen ausführen, indem sie CRTL+Enter (Windows) oder CMD+Enter (Mac) drücken.
Nutzen Sie eine Suchmaschine, wenn Sie nicht wissen welche Funktionen Ihnen ein bestimmtes Ergebnis liefern. Ausserdem können Sie in R immer die Hilfe einer Funktion aufrufen, indem sie vor den Namen der Funktion ein Fragezeichen schreiben, z. Bsp
?medianoder die Hilfe-Funktionhelp()mit dem jeweiligen Funktionsbefehl ausführen:help(median).
Eine zufällig ausgewählte Psychologiestudentin (Stichprobe mit N = 1) hat eine Körpergrösse von 178.7 cm. Sie wissen, dass schweizerische Psychologiestudentinnen genauso gross sind wie alle Schweizerinnen (\(\mu = 165\); \(\sigma = 7\)).
Beantworten Sie die folgeden Fragen für einen Nullhypothesentest, ob die ausgewählte Studentin Grösser als die Population der schweizerischen Psychologiestudentinnen ist:
- Was ist der kritische \(z\)-Wert zur Ablehung der Nullhypothese, für ein Signifikanzniveau von \(\alpha = 1\%\)?
- Was ist der empirische \(z\)-Wert der beobachteten Grösse der zufällig ausgewählten Studentin?
- Was ist der p-Wert die beobachtete Grösse oder extremere Werte zu beobachten?
- Was schliessen Sie aus den berechnetenen Statistiken?
Zuerst sollten wir die relevanten Grössen aus der Aufgabenstellung sammlen:
# Werte aus der Aufgabe
mu <- 165
sigma <- 7
X_emp <- 178.7Für die erste Frage müssen wir die Quantilfunktion der Standardnormalverteilung nutzen um den kritischen z-Wert für ein Signifikanzniveau von 1% bestimmen. In diesem Fall handelt es sich wie in der Vorlesung um eine gerichtete Hypothese, da wir testen ob die zufällig ausgewählte Studentin grösser ist als die Population. Entsprechen berechnen wir den kritischen \(z\)-Wert:
# kritischer Wert für 1% Signifikanz
z_krit <- round(qnorm(p = .99),3)Mit Hilfe der \(z\)-Transformation können wir aus der beobachteten Grösse X_emp den empirischen \(z\)-Wert berechnen:
# empirischer z-Wert
z_emp <- round((X_emp - mu)/sigma,3)Mit dem empirischen \(z\)-Wert und der Verteilungsfunktion der Standardnormalverteilung bzw. der Tabelle können wir nun den \(p\)-Wert bestimmen:
# p-Wert
p_emp <- round(pnorm(z_emp, lower.tail = FALSE),3)In R haben wir natürlich auch die Möglichkeit den kritischen Wert \(X_{krit}\) auf der Skala der Zufallsvariable \(X\) zu berechnen, und den \(p\)-Wert direkt auf Basis des beobachteten Werts der Zufallsvariable \(X_{emp}\) zu bestimmen:
# ohne Standardnormalverteilung / Tabelle
X_krit <- round(qnorm(p = .99, mean = mu, sd = sigma),1)
p_emp <- round(pnorm(X_emp, mean = mu, sd = sigma, lower.tail = FALSE),3)Auf Basis der berechneten Statistiken kommen wir zu dem Schluss, dass wir die Nullhypothese nicht verwerfen. Dazu können Sie einerseits den Betrag des emprischen \(z\)Werts mit dem des kritischen \(z\)-Werts vergleichen. Ein Test ist signifikant, wenn gilt: \(|z_{emp}| > |z_{krit}|\). Dies ist in diesem Fall nicht erfüllt, da: \(|z_{emp}| = 1.957 < |z_{krit}| = 2.326\).
Andereseits können Sie prüfen, ob der berechnete \(p\)-Wert kleiner als das gewählte Signifikanzniveau \(\alpha = 1\%\) ist: \(p < .01\) Dies ist ebenfalls nicht der Fall: \(p = .025 > .01\). Entsprechend können wir die Nullhypothese nicht verwerfen.
Ein männlicher Patient einer Klinik mit Verdacht auf Magersucht hat ein Gewicht von 62.5kg. Das Durchschnittliche Gewicht von schweizer Männer liegt bei 84kg mit einer Standardabweichung von 9kg. Für Magersucht nehmen Sie einen Effekt von Cohen’s \(\delta\) von -2 an. Beantworten Sie die folgenden Fragen für einen Test, ob der Patient ein kleineres GEwicht als die Population hat, nach dem binären Entscheidungskonzept mit einen Signifikanzniveau \(\alpha = 5\%\):
- Was ist der kritische Wert auf der Skala des Gewichts \(X_{krit}\) in kg?
- Was ist der \(p\)-Wert für das beobachtete Gewicht oder extremere Ergebisse?
- Wie gross ist der \(\beta\)-Fehler für diesen Test?
- Welchen Hypothese nehmen Sie auf Basis der berechneten Statistiken an?
Zuerst sollten wir wieder die relevanten Grössen aus der Aufgabenstellung sammlen:
# Werte aus der Aufgabe
mu <- 84
sigma <- 9
X_emp <- 62.5
coh_d <- -2Um den kritischen Wert auf der Skala des Gewichts zu bestimmen können wir erst den kritischen \(z\)-Wert für \(\alpha = 5\%\) bestimmen. Dies können wir anhand der Tabelle oder mit Hilfe der Quantilfunktion der Standardnormalverteilung machen. Dann können wir mit Hilfe des Populationsmittelwerts und der Standardabweichung der \(z\)-Wert in den kritischen Wert auf der Skala des Gewichts bestimmen:
# Kritischer Wert: Skala kg
z_krit <- round(qnorm(p = .05),3)
X_krit <- z_krit*sigma + muin R können wir diesen Wert natürlich auch bestimmen in dem wir die Quantilfunktion mit dem genannten Mittelwert und der Standardbweichung aus der Aufgabe berechnen:
# nicht auf Basis der Standardnormalverteilung:
X_krit <- round(qnorm(p = .05, mean = mu, sd = sigma),3)Um den \(p\)-Wert zu bestimmen, können wir das beobachtete Gewicht \(X_{emp}\) als erstes in einen \(z\)-Wert umrechnen und dann anhand der Verteilungsfunktion der Standardnormalverteilung bzw. der Tabelle bestimmen, wie hoch die Wahrscheinlichkeit für den beobachteten Wert oder extremere Werte ist. Dabei müssen wir beachten, dass wir dieses Mal eine Hypothese testen bei der wir prüfen ob das beobachtete Gewicht kleiner als das Gewicht in der Population ist, deshalb müssen wir die Fläche unter der Verteilung links von den beobachten Wert bestimmen:
# p-Wert
z_emp <- round((X_emp - mu)/sigma,3)
p_emp <- round(pnorm(z_emp, lower.tail = TRUE),3)in R können wir das natürlich auch wieder direkt mit dem Mittelwert und der Standardabweichung aus der Aufgabenstellung machen:
# nicht auf Basis der Standardnormalverteilung:
p_emp <- round(pnorm(X_emp, mean = mu, sd = sigma),3)Zur bestimmung des \(\beta\)-Fehlers müssen wir als erstes Bestimmen welchen \(z\)-Wert der kritische Wert für das Signifikanzniveau \(\alpha = 5\%\) hat: \(z_{H1} = z_{krit} - \delta\). Da wir alle Werte schon auf der Ebenen der Standardnormalverteilung haben, müssen wir dabei nicht durch die Standardabweichung teilen. Anhand diesen \(z_{H1}\)-Wertes können wir nun den \(\beta\)-Fehler bestimmen, indem wir die Wahrscheinlichkeit bestimmen den gleichen oder extremere Werte unter der \(H_1\) zu beobachten. Dafür nutzen wir die Verteilungsfunktion der Standardnormalverteilung:
# beta-Fehler
z_H1 <- z_krit - coh_d
beta <- pnorm(z_H1, lower.tail = FALSE)mit R könnten wir dies wiederum direkt mit dem kritischen \(z\)-Wert und einer Normalverteilung mit einem Mittelwert \(\mu = \delta\) und einer Standardabweichung von 1 bestimmen:
# nicht auf Basis der Standardnormalverteilung
beta <- pnorm(z_krit, mean = coh_d, lower.tail = FALSE)Beachten Sie, dass wir hier die Fläche über den kritischen Wert für die Verteilung unter der Alternativhypothese berechnen müssen. Deshalb müssen Sie den Wert den Sie aus der Tabelle ablesen noch von 1 abziehen: \(\beta = 1 - F(z_{krit})\); in R können wir das mit dem Argument lower.tail = FALSE direkt in der Verteilungsfunktion erreichen. Alternativ könnten Sie natürlich auch: 1 - pnorm(z_H1) rechnen.
![]()