In dieser Übung werden wir üben wie man von Hand und mit Hilfe von R einen t-test berechnet und die jeweiligen Ergebnisse interpretiert. Wenn Sie einige Inhalte der Vorlesung nochmal vertiefen wollen, oder nochmal eine ausführlichere Erklärung für die Anwendung des t-tests in R haben wollen, dann können Sie sich die folgenden Videos anschauen.
Für eine konzeptuelle Wiederholung des t-test auf Grund des fehlenden Podcasts empfehle ich Ihnen die folgenden Videos:
Eine Ausfürhliche Erklärung der Relevanz der t-Verteilung: Das Video geht etwas mehr in die Tiefe als in der Vorlesung liefert aber eine sehr fundierte Erklärung warum wir die t-Verteilung für statistische Tests von Mittelwertsvergleichen mit Hilfe von Stichproben nutzen. Die Funktionen gelten jeweils für Excel und nicht für R
In den folgenden Übungen können Sie entweder den simulierten Datensatz semester_data3.csv nutzen, oder Sie können die in den Aufgaben angegebenen Kennwerte die auf Basis des Datensatzes ausgerechnet wurden verwenden um die jeweiligen Tests von Hand zu rechnen. Der Datensatz enthält die Variablen: geschlecht, nationalität, wohnort, alter, wissen_statistik_start, wissen_statistik_end und grösse.
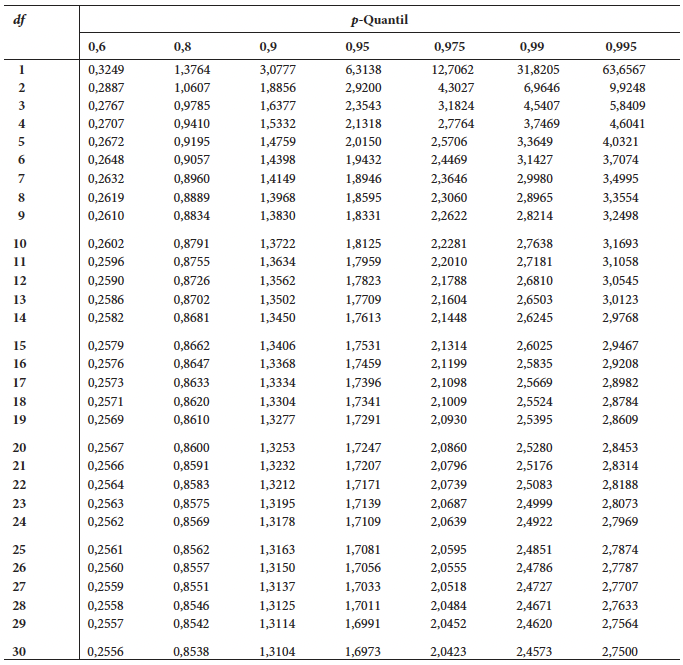
Falls Sie die Übungsfragen nicht mit R beantworten wollen, dann können Sie die hier gedruckte Tabelle der p-Quantile der t-Verteilung nutzen um die Fragen zu beantworten.
Tabelle der p-Quantile der t-Verteilung
Wie in den bisherigen Übungen finden Sie über den Übungsaufgaben die webr Konsole, die Ihnen das Schreiben und Durchführen von R Code direkt auf der Website ermöglicht. Wenn viele Studierenden die Übungen parallel machen, dann kann es sein, dass webr langsam wird.
Um den Code den Sie geschrieben haben auszuführen drücken Sie entweder Run Code, damit der gesamte Code ausgeführt würde. Alternativ können Sie auch einzelne Zeilen ausführen, indem sie CRTL+Enter (Windows) oder CMD+Enter (Mac) drücken.
Nutzen Sie eine Suchmaschine, wenn Sie nicht wissen welche Funktionen Ihnen ein bestimmtes Ergebnis liefern. Ausserdem können Sie in R immer die Hilfe einer Funktion aufrufen, indem sie vor den Namen der Funktion ein Fragezeichen schreiben, z. Bsp ?median oder die Hilfe-Funktion help() mit dem jeweiligen Funktionsbefehl ausführen: help(median).
Sie haben in R mit der Funktion t.test berechnet ob sich das Alter zwischen den Weiblichen und Männlichen Studierenden in den Daten des Datensatzes semester_data3 bedeutsam voneinander unterscheidet. Sie haben dabei folgenden Output erhalten.
Output des in R berechneten t-Tests
Beurteilen, welche der folgenden Aussagen auf Basis des Outputs korrekt sind.
Der Titel des Outputs Two Sample t-test zeigt an, dass es sich um einen t-Test für unabhämngige Stichproben handelt. Für einen Einstichproben t-Test lautet der Title One Sample t-test und für einen t-Test für abhängige Stichproben Paired Sample t-test.
Der empirische \(t\)-Wert kann aus der zweiten Zeile des Outputs abgelesen werden und beträgt: \(t_{emp} = -0.13566\)
Der exakte \(p\)-Wert liegt bei \(p = 0.8931\) was ebenfalls aus der zweiten Zeile des Outputs abgelesen werden kann. Dieser ist auch klar grösser als ein Signifkanzniveau von \(\alpha = .05\)
Aus den letzten Zeilen des Outputs können Sie die Mittelwerte in den beiden Gruppen ablesen. Dabei liegt der Mittelwert der Männer bei \(\bar{x}_M = 22.3\) und der Mittelwert der Frauen bei \(\bar{x}_F = 22.508\)
Die Menge an Beobachtungen in den einzelnen Gruppen lässt sich aus dem Output nicht ablesen. Sie können allerdings auf Basis des Tests \(\rightarrow\)\(t\)-Test für unabhängige Stichproben; und den Freiheitsgrade \(df = 28\) schliessen, dass die Gesamtstichprobengrösse der Gruppe der Männer und Frauen bei \(N = 30\) liegt. Das folgt aus der Formel \(df = (N_1 -1) + (N_2 - 1) = N_1 + N_2 -2\) für die Berechnung der Freiheitsgrade beim \(t\)-Test für unabhängige Stichproben.
Aus der dritten Zeile, die die alternative hypothesis angibt, können Sie ablesen, dass der Test ungerichtet durchgeführt wurde und die Alternativhypothese \(H_1: \mu1 \neq \mu2\) testet, die keine Richtung anzeigt.
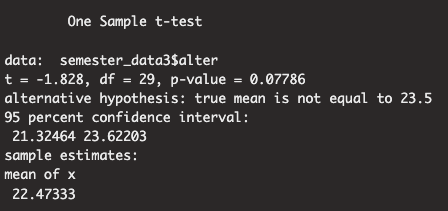
Sie wollen für die Stichprobe aus dem Datensatz semester_data3.csv testen, ob das Alter der Studierenden bedeutsam von dem Durchschnittlichen Alter aller Studierenden im Fach Psychologie \(\mu_0 = 23.5\) abweicht. Der Datensatz enthälte Werte von \(N = 30\) Studierenden. Der Mittelwert des Alters im Datensatz ist \(\bar{x} = 22.5\) und der Populationsschätzer der Standardabweichung aus dem Datensatz ist \(\hat{\sigma} = 3.1\).
Berechnen Sie den entsprechenden t-test um die zwei-seitige Hypothese zu prüfen, dass sich das Alter der Studierenden nicht bedeutsam von dem Wert \(\mu_0\) unterscheidet. Kreuzen Sie an welche der folgenden Aussagen für den Test mit einem Signifikanzniveau von \(\alpha = .05\) zutreffen.
Wichtig: Die Antworten beziehen sich auf die in der Aufgabe angegebenen gerundeten Werte. Wenn Sie den Test mit R auf Basis der Daten ausrechnen, werden Sie aufgrund von Rundungsfehlern auf leicht andere Werte kommen. Bei der Berechnung gehe ich davon aus, dass Sie Zwischenergebnisse auf 3-Nachkommastellen gerundet haben. Die Schlussfolgerung in Bezug auf die Signifikanz des Tests bleibt allerdings unverändert.
Zur Durchführung des \(t\)-Test müssen wir folgenden Schritte durchführen:
Bestimmung des kritischen \(t\)-Werts für die ungerichtete Hypothese mit dem entsprechenden Signifikanzniveau
Diesen Wert können wir direkt aus der Tabelle der \(p\)-Quantile der \(t\)-Verteilung die über den Übungsaufgaben gegeben ist ablesen.
Dabei müssen wir beachten, dass der \(t\)-Test \(df = N - 1 = 30 - 1 = 29\) Freiheitsgrade hat und wir auf Grund der ungerichteten Hypothese das Signifikanzniveau halbieren müssen. Entsprechend müssen wir den \(t\)-Wert für \(df = 29\) und \(p = .975\) aus der Tabelle ablesen. Dieser ist: \(t_{krit}(\alpha = .05) = 2.0452\)
Der in der ersten Antwort angegebenen kritische \(t\)-Wert wäre korrekt, wenn es sich um einen gerichteten Test handeln würde. Dann hätten wir in der Tabelle den \(t\)-Wert für \(df = 29\) und \(p = .95\) ablesen müssen der gerundet \(t_{krit}(\alpha = .05) \approx 1.70\) ist.
Bestimmung des empirischen \(t\)-Wertes auf Basis der in der Frage angegebene Grössen
Den empirischen \(t\)-Wert können wir mit Hilfe des Stichproben-Mittelwerts \(\bar{x} = 22.5\), des Populationsschätzers der Standardabweichung \(\hat{\sigma} = 3.1\) und dem Referenzwert \(\mu_0 = 23.5\) berechnen. Der empirische \(t\)-Wert ergibt sich dabei aus:
Der empirische \(t\)-Wert beträgt damit auf zwei Nachkommastellen gerundet: \(t_{emp} \approx -1,77\)
Bestimmung des \(p\)-Wertes anhand des empirischen \(t\)-Wertes
Anhand der Tabelle der \(p\)-Quantile der \(t\)-Verteilung können wir bestimmen, dass der \(p-Wert\) zwischen \(.10 > p > .05\) liegt.
Dabei sehen wir, dass der empirische \(t\)-Wert zwischen den \(t\)-Werte für \(p = .95\) und \(p = .975\) liegt. Für einen ungerichteten Test berechnet sich der \(p\)-Wert aus \(p = 2 \cdot (1 - F_t(|t_{emp}|, df))\) da wir beachten müssen, dass der \(t\)-Wert den kritischen Wert im negativen wie auch positiven Bereich überschreiten kann.
Daraus ergibt sich, dass der \(p\)-Wert für den berechneten empirischen \(t\)-Wert zwischen .10 und .05 liegen muss und damit nicht kleiner also unser Signifikanzniveau von \(\alpha = .05\) ist.
Auf Basis der Tabelle können wir den \(p\)-Wert leider nicht genauer bestimmen. Aber wir sehen auch anhand des Vergleichs des kritischen \(t\)-Werts mit dem empirischen \(t\)-Wert, dass der Test nicht signifikant ist: \(|t_{krit}| \approx 2.05 > |t_{emp}| \approx 1.77\)
in R
Wenn Sie den \(t\)-Test in R direkt mit dem Datensatz ausrechnen, dann müssen Sie folgenden Befehl eingeben:
t.test(semester_data3$alter, mu =23.5,alternative ="two.sided",var.equal =TRUE) # ist für Einstichproben t-test nnicht unbedingt nötig
als Output sollten Sie dann folgendes Ergebnis erhalten:
Die Werte imn Output unterscheiden sich auf Grund von Rundungsfehlern von den oben berechneten Werten kommen aber zum gleichen Ergebnis.
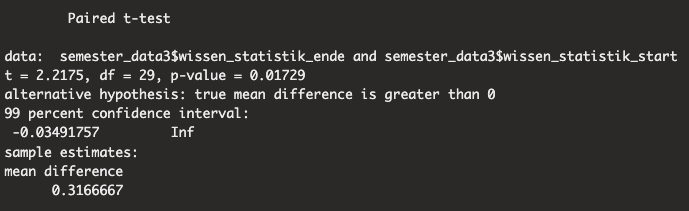
Sie wollen testen, ob sich die Einschätzung des eigenen Wissens im Bezug auf das Fach Statistik von Beginn zum Ende des Semesters bei den Studierenden verändert hat. Dafür wollen Sie einen \(t\)-Test für abhängige Stichproben rechnen. Aus den Daten haben Sie folgenden Kennwerte für die Differenz zwischen dem eingeschätzten Wissen am Ende wissen_statistik_ende und dem eingeschätzten Wissen am Anfang wissen_statistik_start berechnet:
Mittelwert der Differenz: \(\bar{x}_D = 0.32\)
Populationsschätzer der Standardabweichung der Differenz: \(\hat{\sigma}_D = 0.78\)
Berechnen Sie den \(t\)-Test für abhängige Stichproben aus den \(N = 30\) Beobachtungen und nehmen Sie ein Signifikanzniveau von \(\alpha = .01\) an. Sie testen die gerichtete Hypothese, dass das eingeschätzte Wissen am Ende des Semesters grösser als am Anfang ist
Bei diesem \(t\)-Test handelt es sich um einen \(t\)-Test für abhängige Stichproben. Die Freiheitsgrade des Test berechnen sich entsprechend als \(df = N-1 = 30-1 = 29\)
Mit den Freiheitsgraden und dem Signifikanzniveau von \(\alpha = .01\) können wir den kritischen \(t\)-Wert aus der Tabelle der \(p\)-Quantile ablesen. Dafür lesen wir den Wert aus der Zeile für \(df = 29\) und dem \(p\)-Quantil für \(p = 1 - \alpha = .99\) ab. Dieser Werte ist \(t_{krit} (\alpha = .01) = 2.46\)
Der in der zweiten Antwortalternative angegebene kritische \(t\)-Wert ist für ein Signifikanzniveau von \(\alpha = .05\). Hier ist aber ein Signifkanzniveau von \(\alpha = .01\) gewählt worden.
Auf Basis der gegebenen Informationen aus der Aufgabe können wir auch den empirischen \(t\)-Wert berechnen. Für den \(t\)-Test für abhängige Stichproben ergibt sich dieser aus:
Mit dem empirischen \(t\)-Wert können wir aus der Tabelle der \(p\)-Quantile auch das Intervall bestimmen in dem der \(p\)-Wert liegt. Für die Zeile von \(df = 29\) liegt \(t_{emp}\) zwischen dem Wert des \(p\)-Quantils \(p = .975 \rightarrow t = 2.04\) und dem Wert des \(p\)-Quantils für \(p = .99 \rightarrow t = 2.48\). Entsprechend ist der \(p\)-Wert kleiner als .025 aber grösser als .01.
in R
Wenn Sie den \(t\)-Test in R direkt mit dem Datensatz ausrechnen, dann müssen Sie folgenden Befehl eingeben:
als Output sollten Sie dann folgendes Ergebnis erhalten:
Die Werte imn Output unterscheiden sich auf Grund von Rundungsfehlern von den oben berechneten Werten kommen aber zum gleichen Ergebnis.
Sie wollen auf Basis der Daten im Datensatz semester_data3 testen, ob sich die Grösse zwischen weiblichen und männlichen Studierenden unterscheidet. Sie haben dafür folgende Werte Berechnet:
Mittelwerte der Grösse nach Geschlecht: \(\bar{x}_W = 159.04\); \(\bar{x}_M = 179.00\)
Populationsschätzer der Standardabweichung: \(\hat{\sigma}_W = 7.11\); \(\hat{\sigma}_M = 6.12\)
Gruppengrösse in der Daten: \(N_W = 25\); \(N_M = 5\)
Sie testen eine gerichtete Hypothese die Prüft, ob männliche Studierende grösser als weibliche Studierende sind. Sie nutzen dafür ein Signifikanzniveau von \(\alpha = .05\). Beurteilen Sie für den Berechneten Test welche der folgenden Aussagen zutreffen.
Wichtig: Die Antworten beziehen sich auf die in der Aufgabe angegebenen gerundeten Werte. Wenn Sie den Test mit R auf Basis der Daten ausrechnen, werden Sie aufgrund von Rundungsfehlern auf leicht andere Werte kommen. Bei der Berechnung gehe ich davon aus, dass Sie Zwischenergebnisse auf 3-Nachkommastellen gerundet haben. Die Schlussfolgerung in Bezug auf die Signifikanz des Tests bleibt allerdings unverändert.
Bei dem zu berechnenden \(t\)-Test handelt es sich um einen \(t\)-Test für unabhängige Stichproben.
Den kritischen \(t\)-Wert können wir also auf Basis des gegebenen Signifinkanzniveaus \(\alpha = .05\) und den Freiheitsgraden \(df = N_W + N_M - 2\) bestimmen. Aus der Tabelle der \(p\)-Quantile lesen wir also aus der Zeile mit \(df = 28\) und der Spalte für \(p = 1 - \alpha = .95\) den kritischen \(t\)-Wert ab: \(t_{krit}(\alpha = .05) = 1.7011\)
Der in der zweiten Antwort angegebene \(t\)-Wert ist für \(df = 29\). Diese Freiheitsgrade würden aber nur für einen einstichproben\(t\)-Test oder den \(t\)-Test für abhängige Stichproben stimmen
Nun müssen wir auf Basis der gegebenen Werte den empirischen \(t\)-Wert berechnen. Dabei müssen wir die folgenden Schritte durchführen:
Auf Basis des empirischen \(t\)-Werts können wir nun anhand der Tabelle der \(p\)-Quantile auch den \(p\)-Wert bestimmen. Dabei sehen wir, dass der empirische \(t\)-Wert grösser ist als der \(t\)-Wert in der letzten Spalte für das \(p\)-Quantil \(p = .995\)\(\rightarrow t = 2.7633\), daraus können wir schliessen, dass der \(p\)-Wert für die beobachtete Mittelwertsdifferent kleiner als \(p < 1 - .995 = .005\) ist. Damit ist der \(p\)-Wert kleiner als das gewählte Signifikanzniveau \(\alpha = .05\)
in R
Wenn Sie den \(t\)-Test in R direkt mit dem Datensatz ausrechnen, dann müssen Sie folgenden Befehl eingeben:
t.test(grösse ~ geschlecht, # formelschreibweise: av ~ uvalternative ="greater", # gerichtete Hypothesedata = semester_data3, # Datensatz in dem die in der Formel angegebenen Variablen enthalten sindvar.equal =TRUE). # Annahme gleicher Varianzen
als Output sollten Sie dann folgendes Ergebnis erhalten:
Die Werte imn Output unterscheiden sich auf Grund von Rundungsfehlern von den oben berechneten Werten kommen aber zum gleichen Ergebnis.